News Anchors of the Future
In the 1980s, British Channel 4 tried to imagine the TV of the future. They created Max Headroom as the host of a music show. He was supposed to be an AI character although played by an actual human actor, Matt Frewer. After shooting, the fragments were cut in a way that would be called “glitchy” nowadays. This imperfection is a very important part of the character, serving as a signifier for an artificial humanoid character.
When so called neural networks came up, a discussion started about which kinds of labour can be done by so called artificial intelligence. Some people are convinced even artists and musicians will be replaced by computer systems. Hatsune Miku was originally the name voicebank which can be used with Yamaha’s Vocaloid software. From 2010 on, albums for Hatsune Miku have been produced. In 2012 “she” gave her first concert as a holograph, gaining huge popularity.
Max Headroom and Hatsune Miku are popular examples for avatars, fictional characters with a virtual representation created through CGI and video cutting techniques. With this history in mind, how would avatars for TV news look like? Having trained a machine learning model with news host images, the software can generate new news hosts. Most approaches aim at generating a photorealistic representation of a human. Referring to Max Headroom, it is more interesting to create avatars looking human-like, having some flaws, and thus, to include technical characteristics in the design process.
First tests were carried out with the few-show-vid2vid framework by NVIDIA. At this time, the idea was different: The news host were supposed to have dog faces. Due to technical problems this approach was abandoned for now.

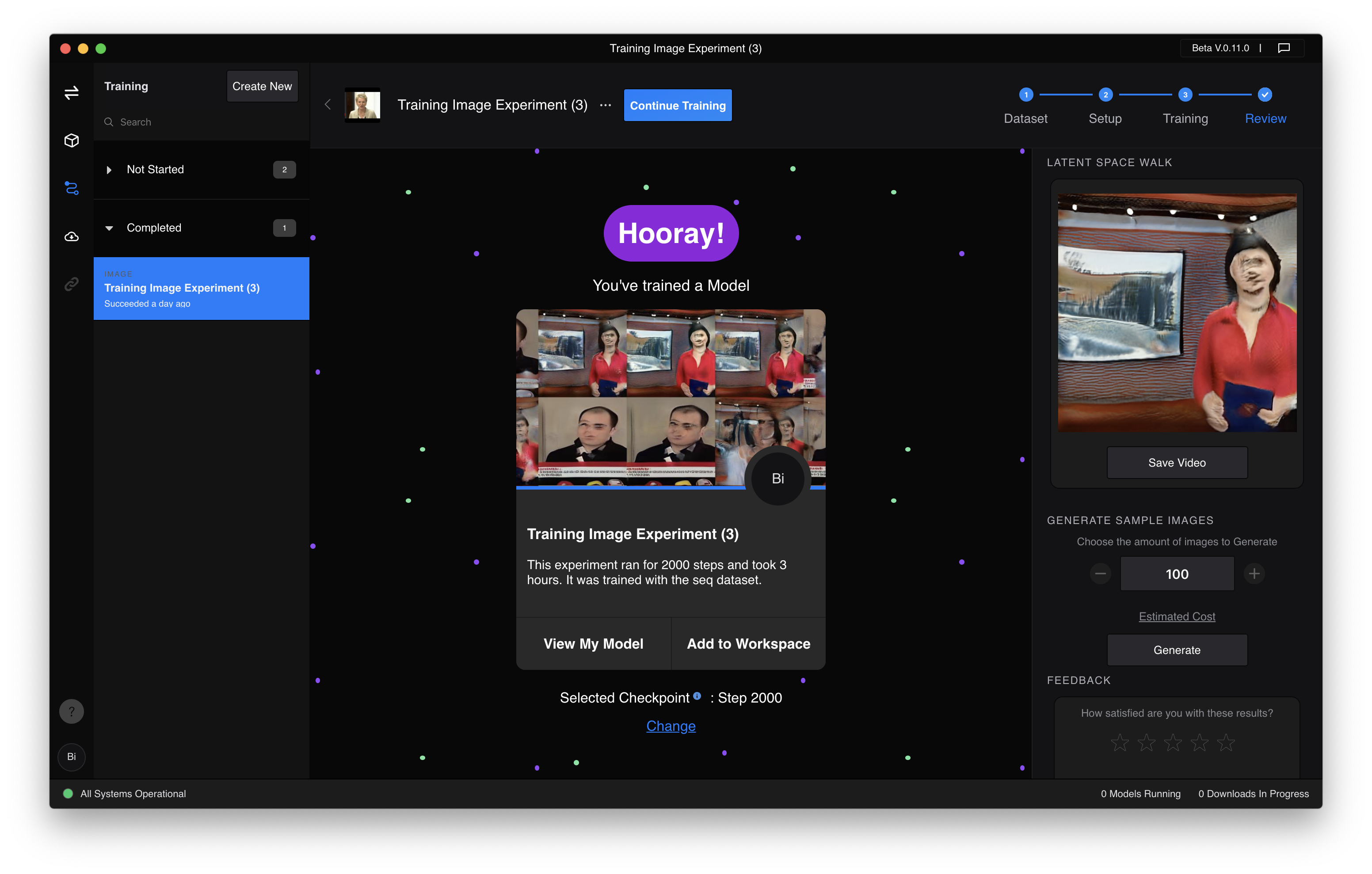
RunwayML is a SaaS company providing shared machine learning models. For this experiment, the StyleGAN (to be more precise StyleGAN2) framework by NVIDIA was used, which gained popularity due to its ability of generating almost photorealistic faces. The model was trained with the FaceForensics dataset by Technische Universität München, consisting of videos of news hosts. Using ffmpeg a part of these video files were converted to image sequences and fed into RunwayML’s training system. After completing the training, a video was generated walking through different parameters for image generation, creating this fluid transition from one host to another. This training was completed after 2000 steps. The model can be expanded and the quality improved by continuing the training.
Dipl.-Künstler Max Neupert
Bauhaus-Universität Weimar
2020